When Confirmed Police Misconduct Still Gets Dismissed
A data-driven look at what happens after the CCRB substantiates misconduct and why race and neighborhood still shape the outcome.
Most people assume the hard part of police accountability is proving misconduct happened.
But this research points to a different problem: even after misconduct is substantiated by an independent oversight agency, accountability is still not applied evenly.
In New York City, the Civilian Complaint Review Board (CCRB) investigates civilian complaints against NYPD officers. When the CCRB finds enough evidence to substantiate misconduct, you might expect the process to move toward discipline or corrective action. But that is not always what happens. In a meaningful number of cases, the NYPD rejects or dismisses those confirmed findings. And according to this analysis, those dismissals do not fall evenly across groups.
This study looks at the question: once misconduct is confirmed, who actually gets accountability, and who does not? More specifically, we examined whether the NYPD’s rate of dismissing substantiated CCRB complaints varies by the ethnicity of the complainant and by the precinct where the incident occurred.
To answer that, we analyzed complaint data from 2006 to 2018 using the NYPD Misconduct Database, supplemented with Census and NYC Open Data sources . Rather than looking at complaints in the abstract, we focused on non-compliance: situations where the CCRB found evidence of misconduct, but the NYPD did not uphold that finding. That distinction matters here: it is not just about who filed complaints but rather what happened after an independent body said the complaint had merit.
Modeling a system that does not behave evenly
Because the primary variable of interest is the count of NYPD none-compliance with CCRB verdict, Poisson-based models were used. Simply, that means we used a statistical approach designed for count data, e.g “how often does this happen?”. Population was used as an exposure term so that complaint outcomes could be interpreted relative to the size of the ethnic group in each precinct and a proxy for civilian / police interaction. Additionally victim count was included as a rough proxy for local crime conditions.

Starting with a Fixed-effect Poisson regression with exposure
The first model was a fixed-effect Poisson regression. At this stage, the goal was simple: estimate how rates of NYPD non-compliance changed by ethnicity and precinct while accounting for differences in population exposure.

That first model already showed an important pattern: complaints involving Black civilians had substantially higher expected rates of non-compliance than complaints involving white civilians, with Hispanic civilians also elevated relative to whites. But this simple Poisson model also revealed a problem. The residual diagnostics showed clear overdispersion, meaning the variance in the data was larger than what the standard Poisson assumption allows. Simply put, complaint outcomes were more uneven and more variable than the simple model could properly account for. That matters because overdispersion can lead to misleadingly small standard errors and overconfident inference.
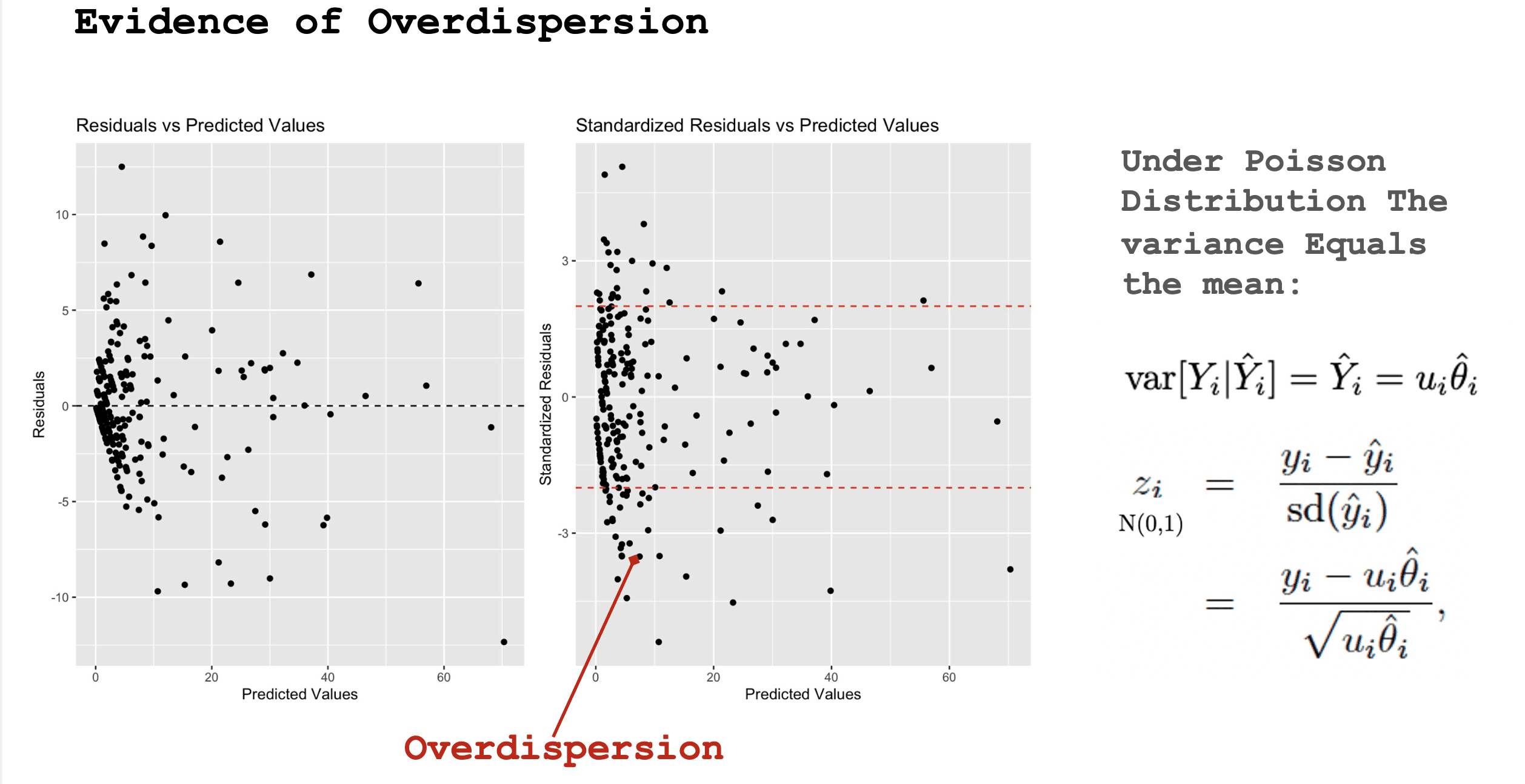
To address this, we next estimated a generalized mixed-effects Poisson model (GLME) with a random intercept for each observation cluster.

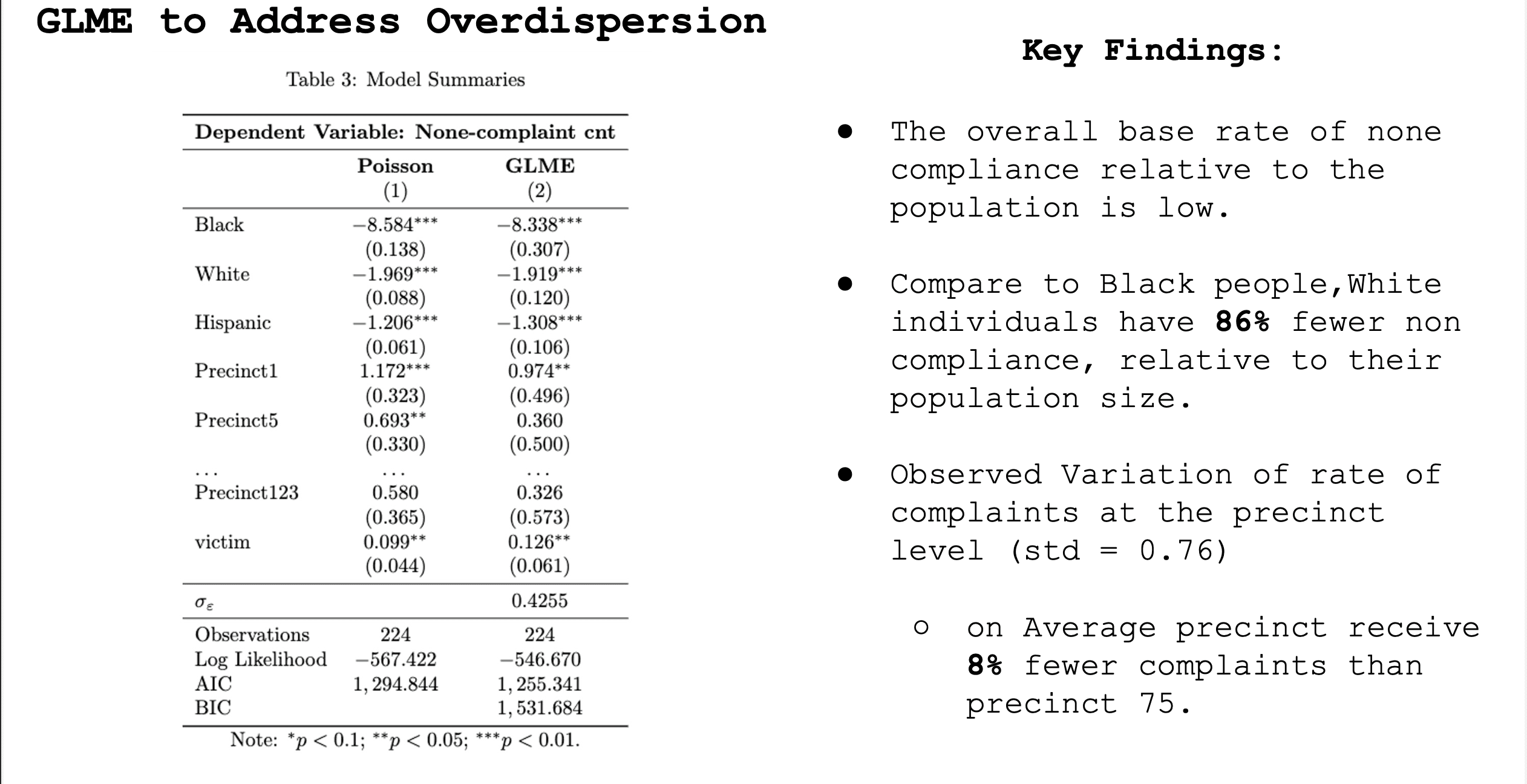
This let the model absorb some of the extra unexplained variation that the basic Poisson specification could not handle. The GLME results preserved the main substantive pattern from the first model, especially the large disparity between Black and white civilians: compared with Black civilians, white civilians had about 86% fewer non-compliance outcomes relative to population size.
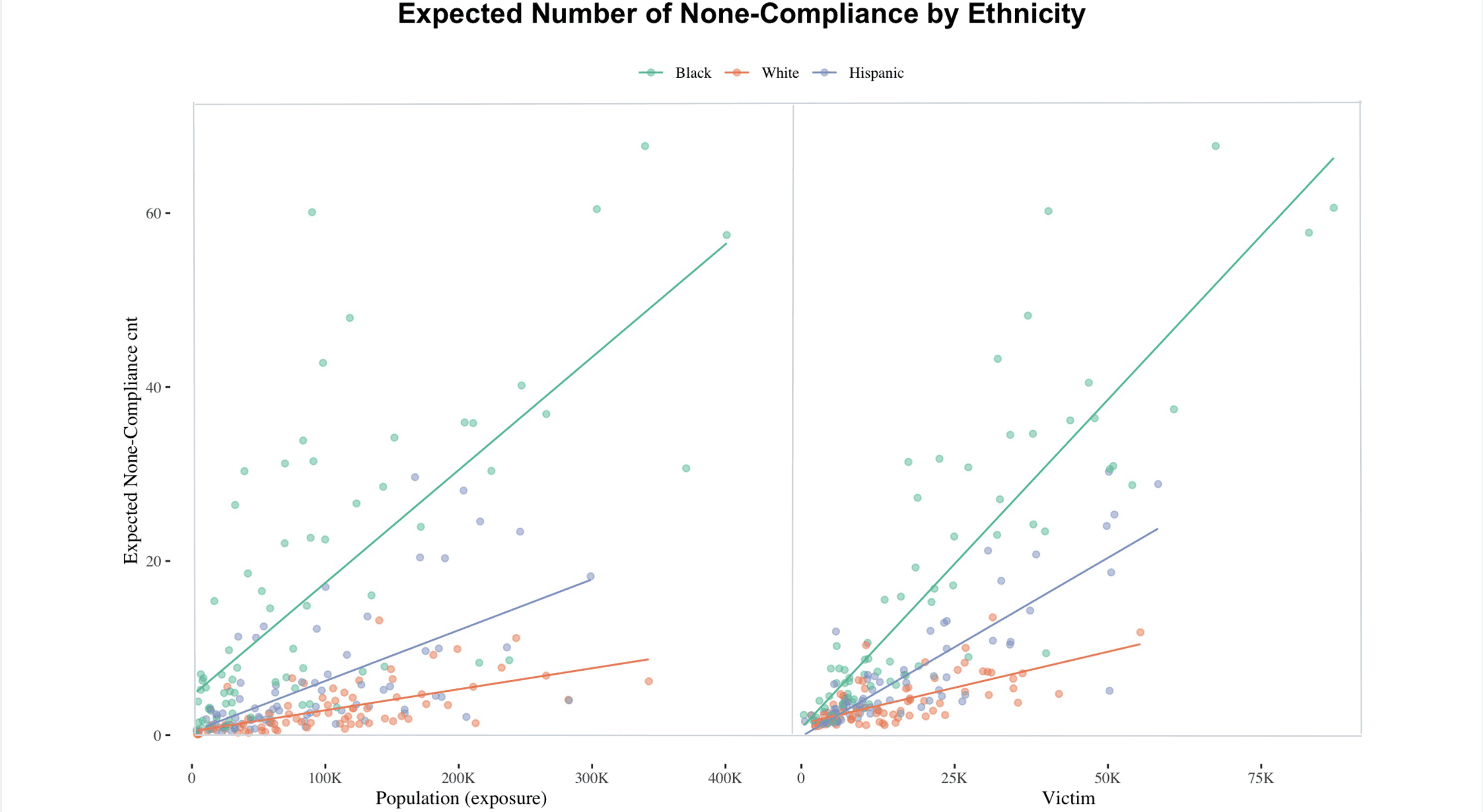
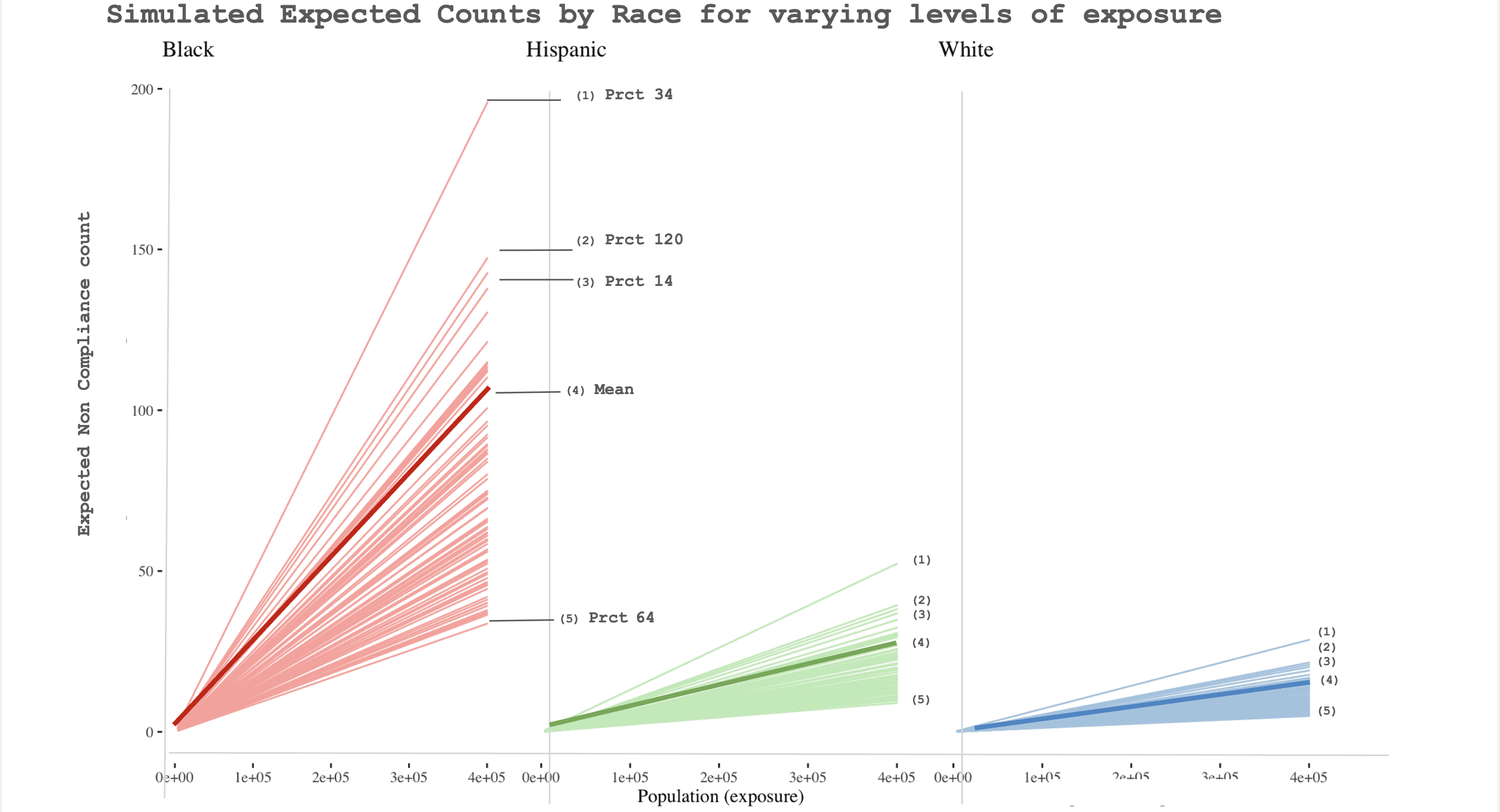
The below expected-count plots makes the disparity visually clear: the slope for Black civilians rises much more sharply than for white civilians, indicating much higher expected non-compliance counts as exposure increases.
These models revealed something else: the rate of complaints also appeared to vary meaningfully across precincts. A precinct-level standard deviation of about 0.76 was observed, with precincts receiving about 8% fewer complaints on average than precinct 75, the reference precinct. That variation is visualized directly in the following precinct estimate chart, where some precincts sit clearly above or below the overall mean
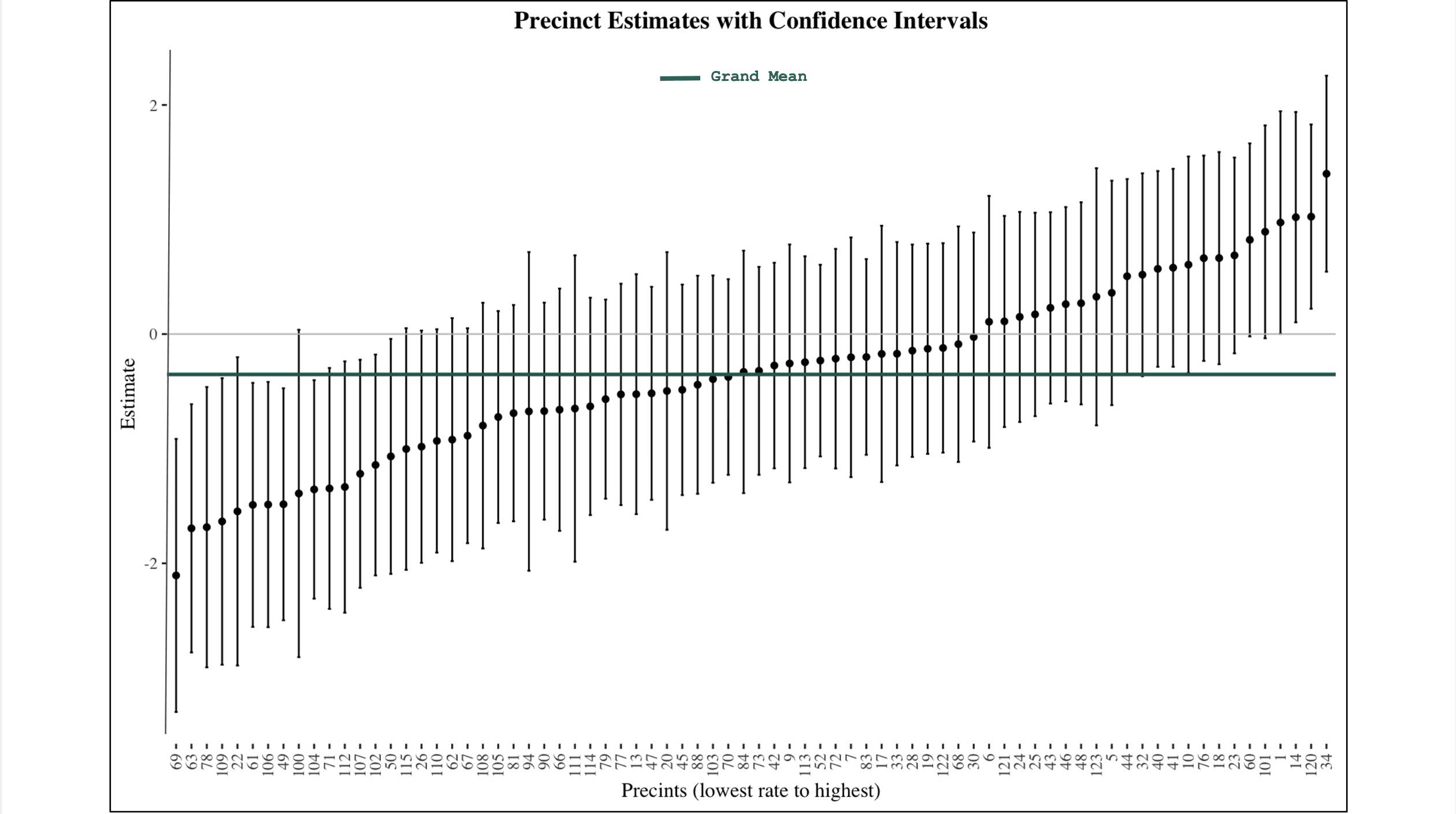
That finding helped motivate the next model; once it became clear that complaint outcomes were not only racially uneven but also geographically uneven, the natural next step was to move beyond correcting overdispersion and start modeling precinct-level structure directly.
Moving to a multilevel model with random intercepts for precincts
To examine that geographic variation more directly, a multilevel model with random intercepts for precincts was used. Rather than treating precinct as just another fixed label, this model allows each precinct to have its own baseline tendency toward higher or lower non-compliance. That allows to explicitly study the variability in non-compliance both within precincts across ethnic groups and between precincts for the same ethnic group. In other words this model helps answer the question: how much of the remaining variation in non-compliance happens within precincts across ethnic groups, and how much happens between precincts themselves?

Turns out the answer is: both matter. The Interclass correlation coefficient (ICC) of 0.37 indicates meaningful between-precinct variation, with about 37% of the variance attributable to differences across precincts. The evidence for within-precinct variation comes from the ethnicity fixed effects, which remain substantively important in the multilevel model, indicating that even after allowing precincts to have different baseline rates, expected non-compliance still differs by ethnicity within the same precinct.
The simulated expected-count plots make this intuitive: rates of non-compliance vary by ethnicity within the same precinct, but they also vary across precincts for the same ethnic group.
This showed that accountability outcomes were not being produced by one uniform citywide system but rather were shaped by local precinct context. But even with that added structure, a sizable amount of unexplained variation remained, which motivated the next question: what precinct-level features might help explain why some precincts look so different from others?
Adding level-2 context and checking sensitivity
To investigate that remaining precinct-level variation, level-2 covariates were introduced: variables that describe the precinct itself rather than the ethnicity-by-precinct observation inside it. Since there was limited access to high-quality precinct-level institutional variables, the population variable was recrafted into a proportion of Black residents in each precinct variable, modeled after Gelman's stop and frisk study.
First, a sensitivity check through stratification. Precincts were divided into three groups based on Black population share: less than 10%, between 10% and 40%, and greater than 40%.
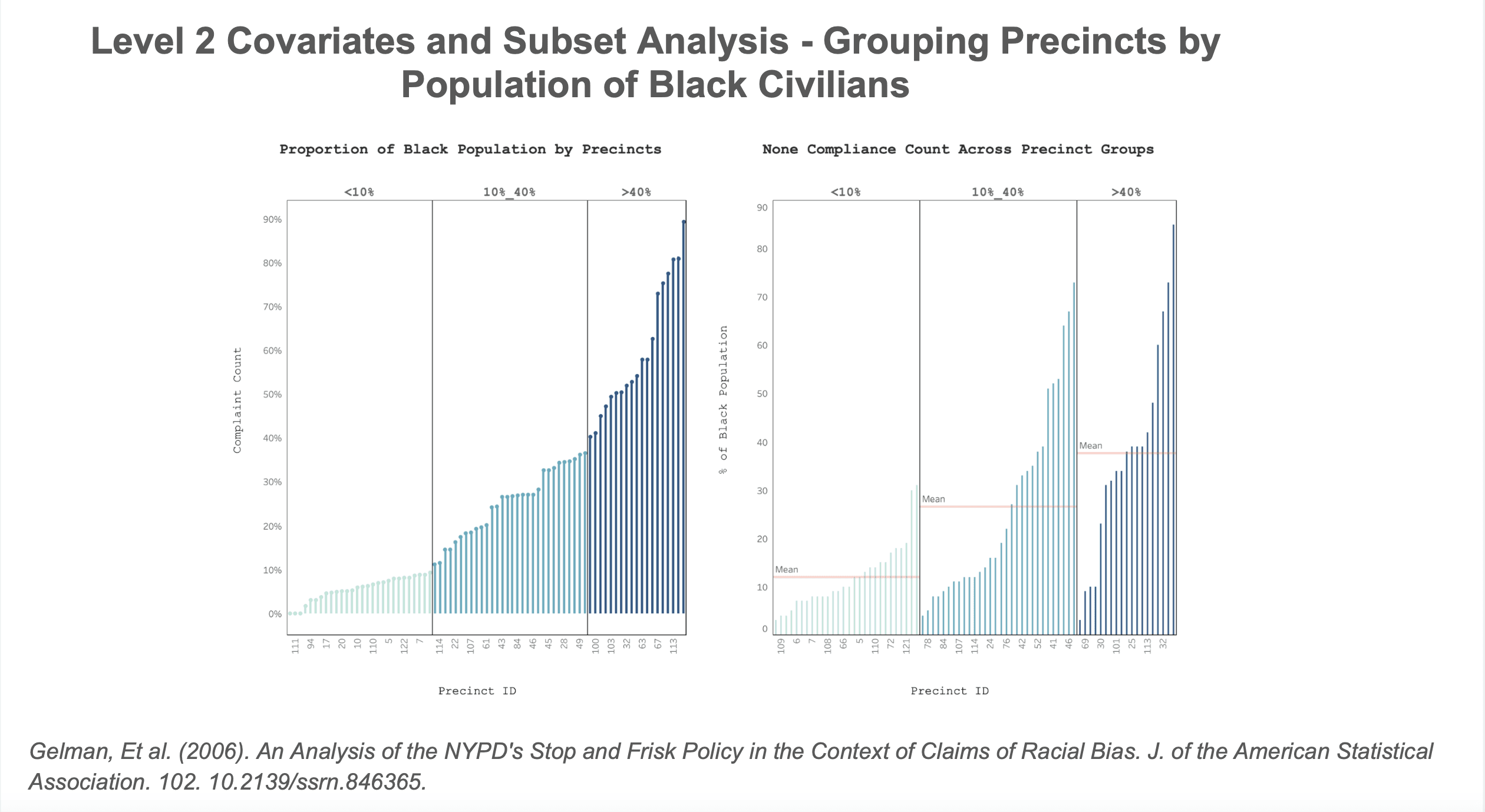
This provides a more interpretable way to see whether neighborhood racial composition was related to the differences observed across precincts.

That sensitivity check showed a striking pattern. Substantiated complaints involving Black civilians had the highest non-compliance rates in precincts with the lowest Black population shares. Black civilians in precincts with less than 10% Black population faced much higher dismissal rates than those in predominantly Black precincts. By contrast, the rates for white and Hispanic civilians were much flatter across these same strata.
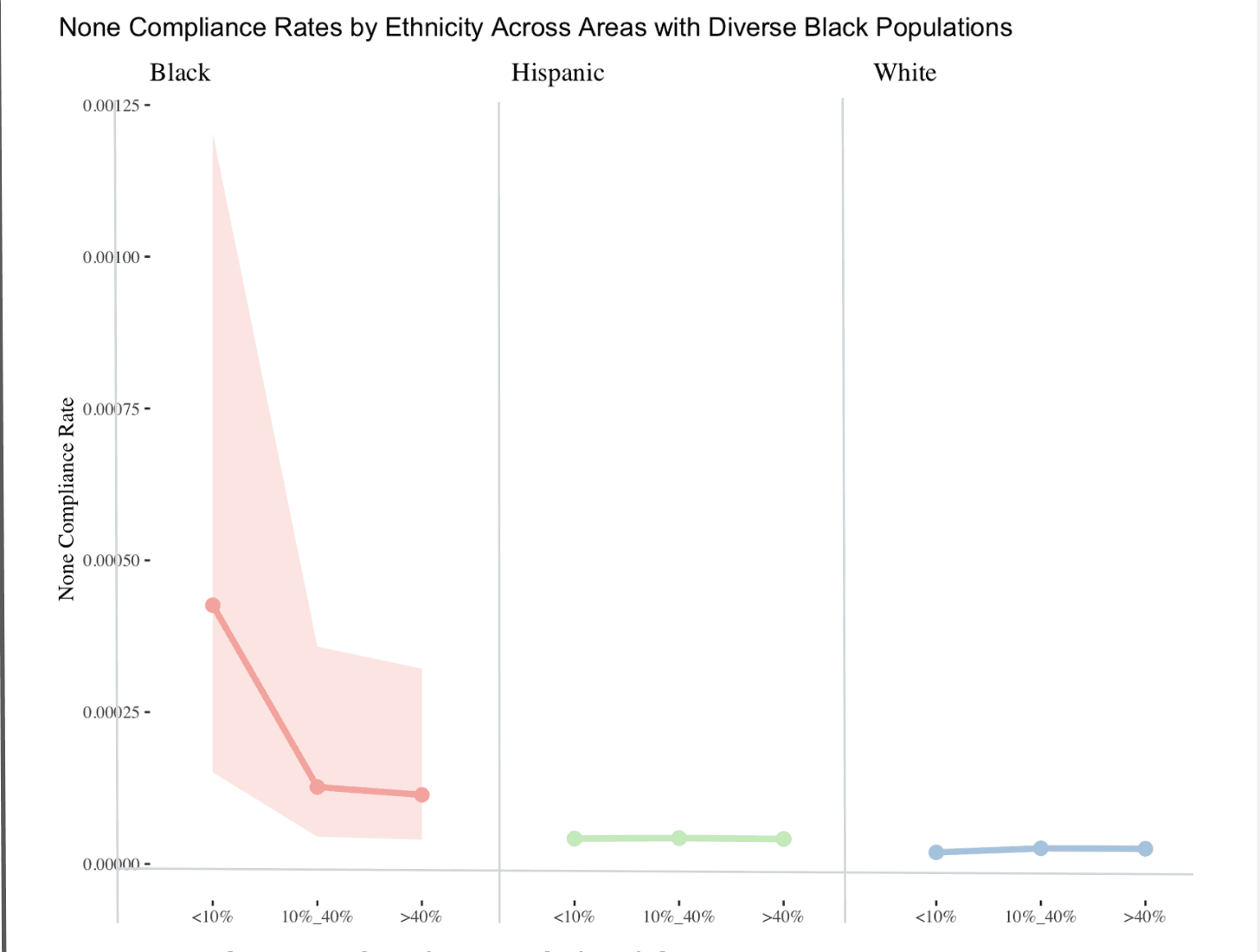
This idea was then incorporated directly into the final pooled multilevel model by adding Black population share as a level-2 precinct covariate .

The resulting model supported the same general story: as the Black share of a precinct increased, the expected rate of non-compliance affecting Black civilians decreased. Put plainly, complaints involving Black civilians were more likely to be dismissed in less-Black precincts than in more-Black precincts.
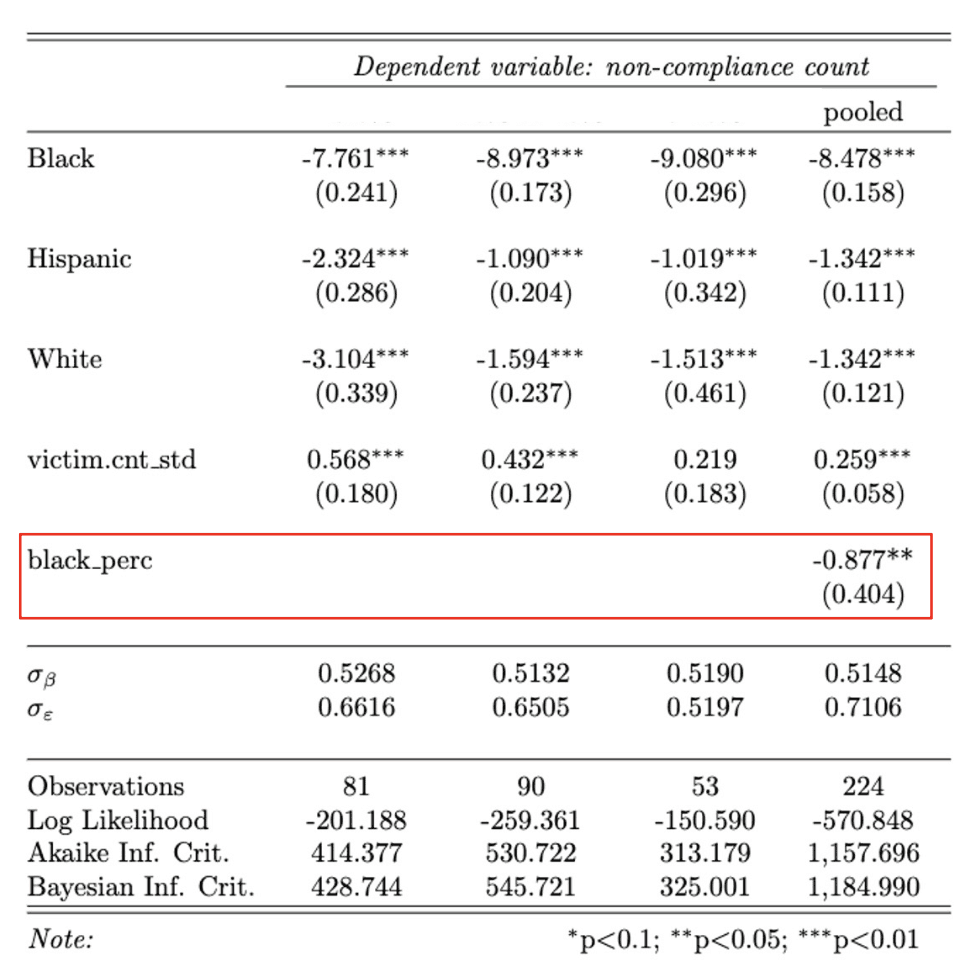
That helped explain some of the geographic pattern, but not all of it. The level-2 covariate improved interpretation, yet substantial residual variation remained. So the conclusion from this final stage was not that demographic composition fully explains the disparity but rather that precinct context matters, and racial composition appears to be part of the story.
Limitations and what this study still can’t explain
The patterns in the data are strong, but the models do not explain everything. Even after accounting for ethnicity, exposure, victim counts, precinct-level random effects, and the racial composition of precincts, substantial residual variation remained. That is usually a sign that important precinct-level factors are still missing from the model.
Just as important, this study identifies differences in outcomes, not the full causal mechanism behind those differences. In other words, we can show that substantiated complaints were handled differently across ethnic groups and precincts, but we cannot say from these models alone exactly why those differences occurred. The analysis does not prove discriminatory intent, racist practice, or other foul play by any individual officer or precinct. There may be other institutional, operational, or contextual factors at work, including unmeasured complaint characteristics, officer histories, precinct culture, local administrative practices, or differences in the types of encounters that generate complaints, that are not captured in the current data. What the study does show is that the disparities are present and statistically meaningful; what it cannot yet fully explain is the mechanism producing them.
One likely gap is the lack of richer level-2 covariates: variables that describe the precinct itself. Future work could look at local public sentiment, officer characteristics such as training, pay grade, promotion history, and prior disciplinary records, all of which could shape how substantiated complaints are handled. In other words, the current models show that precinct context matters, but they do not yet capture all of the reasons why it matters.
There are also modeling choices that could be improved. The exposure variable was population, which is useful for normalization, but it is only a rough stand-in for the true number of civilian-police interactions. A better exposure would more closely reflect actual encounters between police and civilians, though using complaint-based quantities as predictors raises concerns about data leakage.
A more granular next step would be to move from grouped count models to complaint-level modeling. Disaggregating the data and using logistic regression on binary outcomes, with complaint-specific covariates included at level 1 would be interesting. That would allow a more detailed test of whether the same patterns hold once the unit of analysis is the individual complaint rather than the ethnicity-by-precinct cluster. Another promising extension would be random slopes modeling, which could test whether the ethnicity effect itself changes across precincts rather than only allowing precincts to have different baseline intercepts.
Conclusion
The central takeaway from this study is that once misconduct is substantiated, accountability does not appear to be applied evenly.
Across the models, substantiated complaints involving Black civilians were dismissed by the NYPD at far higher rates than comparable complaints involving white civilians, roughly six to seven times higher. These ethnic differences appear within precincts and across precincts themselves.
In addition, the disparity was not constant across the city. Precinct context mattered. For instance, substantiated complaints involving Black civilians in precinct 34 faced roughly twice the likelihood of dismissal compared with similar complaints in precinct 64, pointing to meaningful between-precinct variation in how accountability is carried out. Precinct 34 has been identified in prior reporting as having among the highest numbers of substantiated misconduct complaints, while also experiencing rising crime levels in recent years. This combination of high complaint volume and policing intensity may contribute to institutional variation in accountability outcomes.
When precincts were grouped by Black population share, the disparity was strongest in places with the lowest Black population, suggesting that neighborhood context is part of the story too.
Taken together, the results point to something bigger than a statistical pattern. They suggest that even after an independent oversight body confirms misconduct, the path to accountability is shaped by both race and place. That does not mean the models answer every question. But they do show, clearly, that the system is not behaving uniformly and that understanding why should be the next step.